
Specialization: Node Scripting
What is node scripting?
Node scripting is a way of creating game logic using visual blocks. The purpose is to allow level designers the freedom of crafting their game's behaviors and interactions without requiring them to write code.
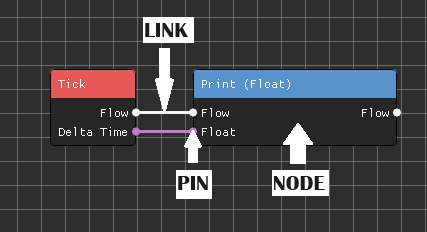
Summary
This page contains an overview of a node scripting system I have created. From a level design perspective, the system supports:
- General behavior scripting (Creating logic visually)
- Custom Events
- Variables
- Command Tracking / Undo + Redo functionality
From a programmer's perspective, the system supports:
- Function based nodes
- Custom data type handling
Background
Implementing a modular gameplay system is something that has intrigued me since the start of the Stella's Quest project. Since all of my previous systems have been inheritance based, I wanted to try to create something that didn't use classes and virtual functions to enable different behaviors.
Programming Interface
The most important part of creating systems and APIs, in my experience, is the interface to the user. The interface should be simple and effective, both for programmers, when implementing new nodes, and for level designers, when creating the actual game logic visually.
An intuitive approach to creating nodes involves defining node types through functions. This method allows programmers to easily define functions that have specific behaviors, and then register them to a manager responsible for converting these functions into node types. In this model, the parameters of a function serve as the node's input, while its return values serve as the node's output.
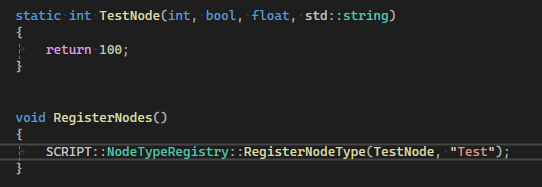
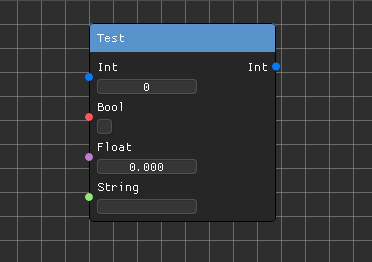
Since a function in most languages, C++ included, only allows one return value, the container std::tuple was utilized to enable functions to return multiple values in a single data structure.
The implementation heavily relies on templates, meaning many processes can occur in compile time. For example, data allocation for pins are based on the data types of the functions.
Execution
The execution part of the code uses a type called Flow that acts as the control flow of the program. We can check in compile time if a node has a Flow output, and if that's the case we trigger the connected node to the flow pin.
When executing a node, the program does the following:
- Retrieves the input data of the node
- Calls the function and retrieves its output data
- Set the output data of the node
Memory Management
As we need to be able to allocate essentially any data type in our system, we need to use a data structure that supports this flexibility. The Memory Pool enables us to store various data types in contiguous memory. In essence, it is implemented as a vector but without the type safety.
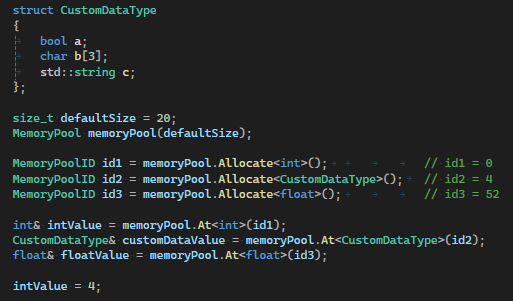
In the above image, we allocate different types to the memory pool. When allocating a variable to the memory pool, the user receives an ID they can use to access the data. This is opposed to receiving a pointer to the data as we need the memory pool to be relocatable and if we have a pointer to the data, the pointer will have a chance of going out of scope if the memory pool reallocates.
The memory pool realizes when it is out of memory and reallocates its memory internally, while simultaneously increasing it's size, just like a vector.
When creating a node, the input/output pins allocate memory in the memory pool and keep the ID stored for usage when the needing to access the data when the node is executed.
Type Erasure
As the execution part is all templated and set at compile time, the program knows how to handle the data types that the node functions use. The problem is when we want to visualize, save and load different data types; How can the user register custom data types that the system handles polymorphically?
To be able to handle various data types, including custom data types that the user wants, I used a technique called type erasure. The system is essentially type agnostic, meaning it doesn't know or care about the types that it uses.
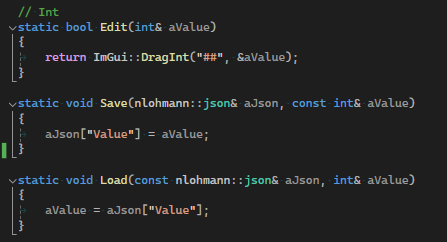

For example, when implementing a custom data type, the type needs the overloaded functions "Edit", "Save" and "Load". When registering the type, the system itself figures out which overloaded function to call in compile time.
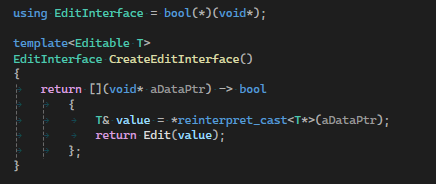
When registering a type, we can create a type erased interface that allows us to perform functionality on data without knowing which type they are. As seen in the above image, the function pointer that is returned from the function is completely type erased, meaning when using it, we don't know which type we are editing. The function signature is type erased while the implementation is not, this is the key to type erasure.
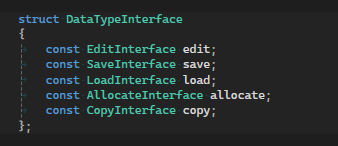
When calling the edit function for a type, you still need some type of identifier to know which type we are dealing with. The thing that the data is bound to, for example a pin, can store a DataTypeID to remember the underlying data type.
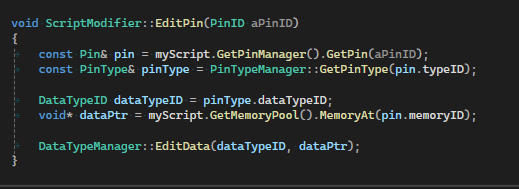
When we have the DataTypeID and the pointer to the data, we can call the edit function of our type. The DataTypeManager has a map with the DataTypeID as the key and the type erased object as the value. This way we can select the correct function to call.
One thing to note is that the DataTypeID of a type has to be unique for that type. If we have a hash collision, the system will assert.
Custom Event Nodes
Type erasure not only allows us to have polymorphic behavior with types, it enables runtime generation of nodes with customized pins.
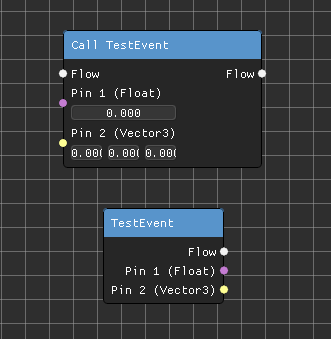
Custom event nodes, inspired by those found in Unreal Engine, are implemented in my system. The user can call the event at any time in the graph using a "caller node" and the functionality attached to the "executor node" will be executed.
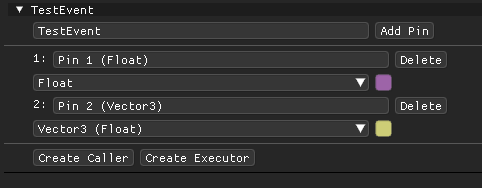
In the editor, the user can create custom event nodes with attached data types. This allows output of the custom event to be flexible depending on who the caller is.
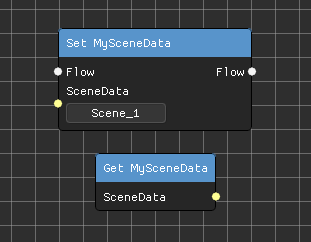
Variables
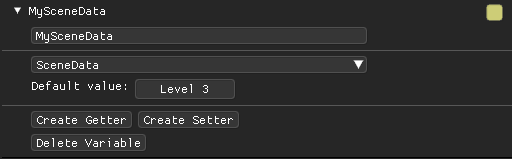
Similar to Unreal Engine, the system also accommodates variables. This allows users to store and manipulate variables using getter and setter nodes. This functionality creates dynamic scripting capabilities, enabling runtime modifications to the inputs used during execution.
Improvements
The are a lot of things that can be improved with the system. This includes:
- Allowing references as inputs to the node functions (not possible currently due to the restrictions of reference declarations.
- Enabling default values as inputs.
- A lot of needed functionality for editor purposes, such as copying/pasting of nodes and node collapsing.